p:: Database
-
Data Warehouse software project built on top of Apache Hadoop for providing data query and analysis
-
Familiar
- Query data with a SQL-based language
-
Fast
- Interactive response times, even over huge datasets
-
Scalable and Extensible
- As data variety and volume grows, more commodity machines can be added, without a corresponding reduction in performance
-
Compatible
- Works with traditional data integration and data analytics tools
Architecture
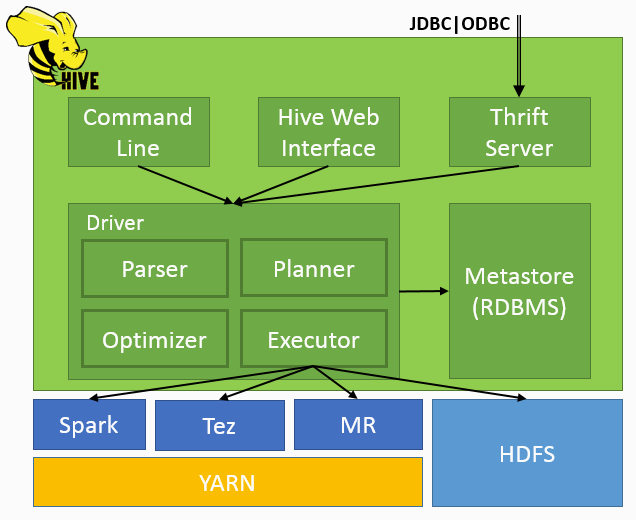
| Component | Description |
|---|---|
| Hive Clients | Apache Hive supports all application written in languages like C++, Java, Python etc. using JDBC, Thrift and ODBC drivers |
| Hive Services | Hive provides various services like web Interface, CLI etc. to perform queries |
| Meta Store | Repository for metadata which consists of data for each table like its location and schema |
| Processing framework | Spark, Tez, MapReduce |
| Resource Management | YARN (Yet Another Resource Negotiator) |
| Distributed Storage | Uses the underlying HDFS for the distributed storage |
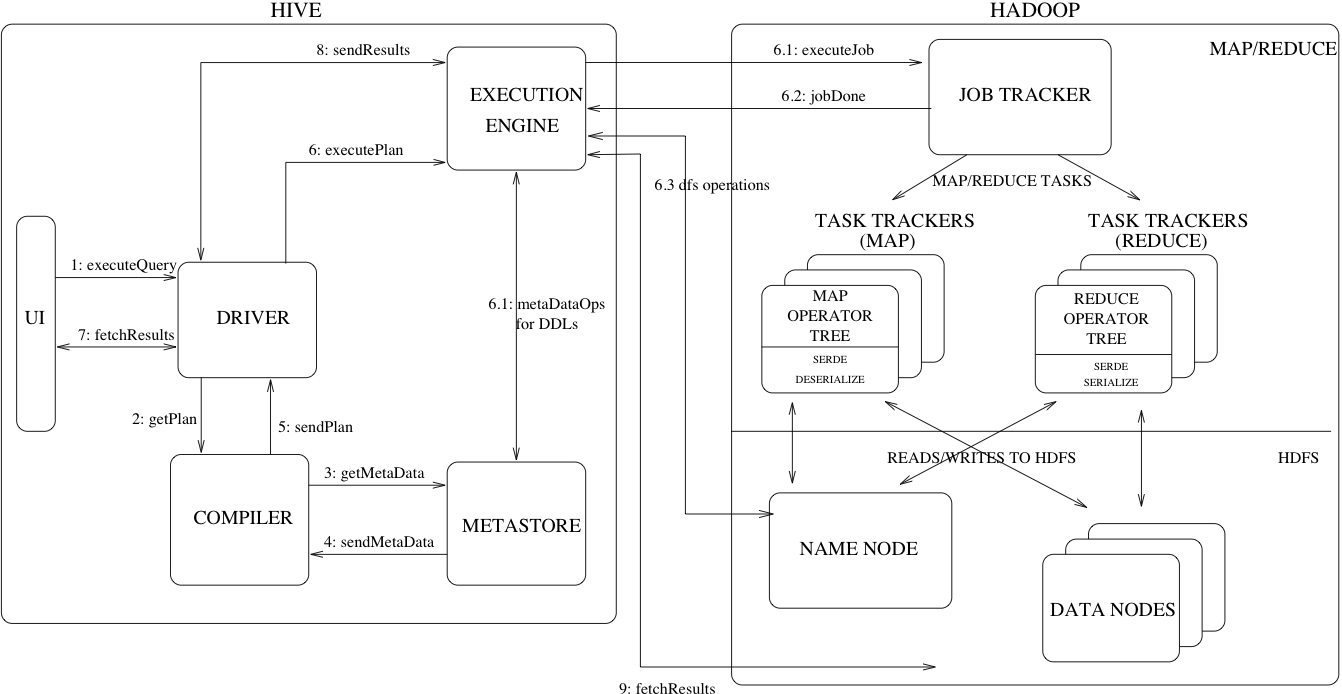
Hive Data Model
HiveQL Data Types
Primitive types
- Numeric data types:
TINYINT,SMALLINT,INT,BIGINT,FLOAT,DOUBLE,DECIMAL - String data types:
STRING,VARCHAR,CHAR - Date/Time data type:
TIMESTAMP,DATE - Miscellaneous data types:
BOOLEAN,BINARY
Complex types
- Structs:
STRUCT<col_name:data_type[COMMENT col_comment],...> - Maps:
MAP<primitive_type,data_type> - Arrays:
ARRAY<data_type> - Union Types:
UNIONTYPE<data_type,data_type,...>
Operators
Built In Operators
- Relational Operators:
A = B,A BETWEEN B AND C,A REGEXP B - Arithmetic Operators:
A + B,A & B,~A - Logical Operators:
A AND B,A IN (value1, value2, …),NOT EXISTS (subquery) - Operators on Complex Types:
A[i],M[key],S.a
Functions
Built In Functions
- Mathematical functions:
rand(...),pi(...) - Collection functions:
size(...) - Type conversion functions:
cast(...),binary(...) - Date functions:
year(...),month(...) - Conditional functions:
coalesce(...),if(...) - String functions:
upper(...),trim(...) - Aggregate functions:
sum(...),count(*) - Table-generating functions:
explode(...),json_tuple(...)
User-Defined Functions
- UDF: User-Defined Function
- UDAF: User-Defined Aggregating Function
- UDTF: User-Defined Table-Generating Function
Partitioning and Bucketing
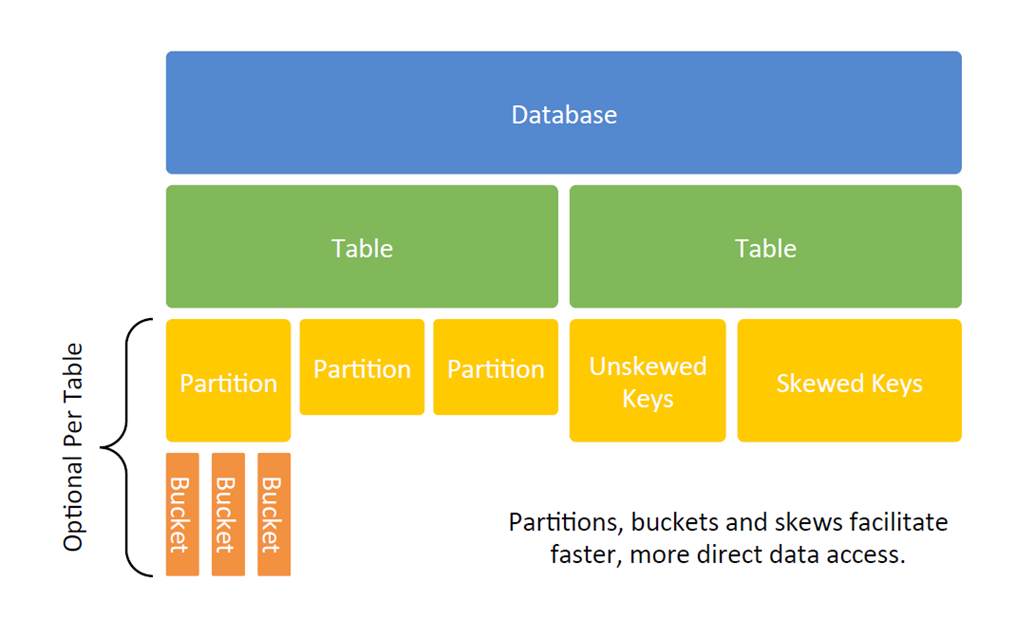
Tables
There are two main types of table in Hive - Managed tables and External tables.
Partitioning
Hive organizes tables into partitions for grouping similar type of data together based on a column or partition key. Each Table can have one or more partition keys to identify a particular partition. This allows us to have a faster query on slices of the data.
Bucketing
In bucketing, we specify the fixed number of buckets in which entire data is to be decomposed. Bucketing concept is based on the hashing principle, where same type of keys are always sent to the same bucket.
File Formats
| Format | Description |
|---|---|
| TEXTFILE | This is the default format specification in Hive. A text file is naturally splittable and able to be processed in parallel. |
| SEQUENCEFILE | This is a binary storage format for key/value pairs. The benefit of a sequence file is that it is more compact than a text file and fits well with the MapReduce output format. |
| AVRO | This is also a binary format. More than that, it is also a serialization and deserialization framework. |
| RCFILE | The Record Columnar File splits data horizontally into row groups and allows Hive to skip irrelevant parts of the data and get the results faster and cheaper. |
| ORC | Optimized Row Columnar provides a larger block size of 256 MB by default (RCFILE has 4 MB and SEQUENCEFILE has 1 MB), optimized for large sequential reads on HDFS. |
| PARQUET | Parquet has a wider range of support for the majority of projects in the ecosystem and leverages the best practices in the design of Google’s Dremel to support the nested structure of data. |
User-Defined Functions
User-defined functions provide a way to use the user’s own application/business logic for processing column values during an HQL query. Hive defines the following three types of user-defined functions, which are extensible:
- UDF: It stands for User-Defined Function, which operates row-wise and outputs one result for one row, such as most built-in mathematics and string functions.
- UDAF: It stands for User-Defined Aggregating Function, which operates row-wise or group-wise and outputs one row for the whole table or one row for each group as a result, such as the
max(...)andcount(...)built-in functions. - UDTF: It stands for User-Defined Table-Generating Function, which also operates row-wise, but produces multiple rows/tables as a result, such as the
explode(...)function. UDTF can be used after theSELECTorLATERAL VIEWstatement.
Although all In functions in HQL are implemented in Java, UDF can also be implemented in any JVM-compatible language, such as Scala.